
Implementación alternativa de algoritmos de aprendizaje (parte I).
overxfl0w13, 25 Mar 2016Estrenaré el blog con el inicio de una serie de entradas que dedicaré a implementar algoritmos de aprendizaje usando la librería Scipy y más concretamente, su módulo optimize (tenía pensado usar Petsc, pero no he conseguido convertir matrices a su formato y me ha complicado las cosas).
Dicho módulo nos permite realizar varios métodos de optimización y búsqueda de raices de funciones (nos centraremos en la parte de optimización de momento y tal vez vea optimizaciones alternativas p.e. usando métodos iterativos de Krylov, que son de mucha utilidad a la hora de resolver sistemas muy grandes de forma eficiente) como pueden ser (no comentaré todos los métodos de cada tipo de optimización):
-
Optimización local: permite minimizar (y si cambiamos de signo maximizar) funciones, variando una serie de parámetros del optimizador como el método de optimización local empleado (Gradiente conjugado, BFGS, Método de Powell …). Al ser un método local , puede quedar atascado en mínimos locales por lo que, si la solución obtenida no es suficientemente buena, se pueden obtener nuevas soluciones de varias formas p e. reinicialización aleatoria, son computacionalmente baratos.
-
Optimización de ecuaciones: entre los que se puede encontrar el método de mínimos cuadrados ampliamente conocidos en regresión y optimización
-
Optimizaciones globales: al contrario que los métodos locales, éstos nos proporcionan soluciones óptimas pero son más costosos ya que requieren comprobar el espacio de soluciones completo (a no ser que se disponga de información que lo acote).
-
Ajustes de funciones (fitting): dada una función f, encontrar una función g que la aproxime, solo está disponible el método mínimos cuadrados para aproximación discreta.
En esta primera entrada comentaré la idea general e implementación de 2 algoritmos de aprendizaje básicos (ambos redes neuronales de una única capa): Perceptron y Adaline se verán sus versiones lineales (aunque es fácilmente generalizable a funciones no lineales usando kernels en cierta parte del código que comentaré) haciendo uso de técnicas de optimización sin restricciones (en la siguiente entrada se verá como añadir restricciones y cotas). Por ello, para comprobar los resultados del entrenamiento y del test se utilizará un conjunto de muestras que variará dependiendo del algoritmo que esté comentando.
Perceptron
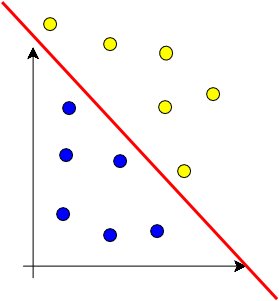
Es un clasificador (en 2 clases {+1,-1} es el que trataremos) basado en funciones discriminantes lineales, el objetivo es encontrar un vector θ que defina un hiperplano separador p.e. una recta en 2D, que separe correctamente el conjunto de muestras en 2 clases. Esto equivale a resolver un sistema de N inecuaciones c·θ·x≥0 (nótese la notación matricial, si se hace vector a vector, equivaldría a resolver ésto)
{kind=link}
{kind=link}
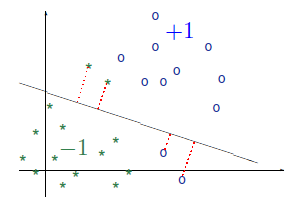
Ese sistema de N inecuaciones con |θ| incógnitas es demasiado costoso de resolver mediante métodos directos (aunque podríamos haber empleado otros métodos iterativos como los que iba a utilizar en Petsc) y por ello, se opta por minimizar ésta función ( suma de las distancias de cada muestra mal clasificada al hiperplano separador) equivalente a resolver el sistema original. Este proceso se suele hacer de forma iterativa, calculando cada vez la suma de las distancias mencionada antes, modificando de acuerdo a esas distancias el valor de θ y repitiendo el proceso hasta que θ converge,varía muy poco, se acaban las iteraciones … .Sin embargo, podemos ahorrarnos la implementación del método iterativo haciendo uso del módulo comentado antes, configurando correctamente la función objetivo a optimizar, las cotas, las restricciones (en entradas posteriores se verán, cuando se implementen máquinas de vectores de soporte SVM), la tolerancia etc. Otra cosa a tener en cuenta es que Perceptron siempre converge si las muestras son linealmente separables.
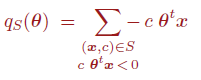{kind=link}
{kind=link}
El código es el siguiente:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# Perceptron.py
from scipy.optimize import minimize
import numpy as np
from Utils import MatLoad
def f(theta,X,Y):
res = np.multiply(theta*X,Y)
if np.array_equal(res>=+0,Y>=+0): return -9999999
else: return (-res[res<0]).sum(1).item((0,0))
def fit(theta,X,Y):
XROWS,XCOLS,YROWS = X.shape[0],X.shape[1],Y.shape[0]
return minimize(fun=f,x0=theta,args=(X,Y),method="CG")
def classify(theta,X): return 1 if np.inner(theta,X)>=+0 else -1
def predict(theta,X): return np.inner(theta,X)
if __name__ == "__main__":
X = MatLoad("X.np");
Y = MatLoad("Y.np");
XROWS,XCOLS,YROWS = X.shape[0],X.shape[1],Y.shape[0]
theta = np.array([-0.0003,-1.54,-3.78])
res = fit(theta,X,Y)
print "\n Detalles de convergencia \n"
print res
theta = res.x
print "\nClase de [1,0,5]:",classify(theta,np.array([1,0,5]))
Para la implementación, se han desarrollado únicamente 4 funciones:
-
f: es la función objetivo que he mencionado antes, se pasará como parámetro al solver de scipy para minimizar. Se hace un producto vector-matriz para calcular la parte c·θ·x y se comprueba si todas las muestras están bien clasificadas, si lo están queremos que el proceso finalice luego devolvemos una distancia muy pequeña, si no lo están devolvemos la suma de las distancias de las muestras mal clasificadas al hiperplano separador.
-
fit: se encarga de llamar al optimizador de Scipy minimize, utilizando el método del gradiente conjugado para entrenar el sistema. Podemos hacer uso de todos los demás métodos implementados en la librería para el optimizador local minimize.
-
classify: una vez entrenado el sistema (obtenido el vector θ adecuado), dada una nueva muestra x permite clasificarla en la clase correcta según θ. Para ello se calcula el producto escalar θ·x y se comprueba si está a un lado del espacio definido por el hiperplano separador o al otro ( θ·x≥0 , θ·x≤0 ).
-
predict: dada una muestra x permite hacer regresión una vez el sistema ha sido entrenado. Con ello, se predice el valor de x dado el vector de parámetros θ, en función del resultado del producto escalar θ·x.
Una vez se han definido las funciones necesarias, solo queda ver cómo se comporta el sistema entrenándolo y probándolo. Para ello, se ha hecho uso de un conjunto de muestras de juguete (en notación homogénea) junto con sus salidas, diseñado a mano:
Muestras de entrenamiento: 3 muestras de 3 dimensiones dispuestas por columnas.
| nº | x1 | x2 | x3 |
|---|---|---|---|
| d1 | 1 | 1 | 1 |
| d2 | 0 | 2 | 4 |
| d3 | 5 | 1 | 2 |
Salidas: salidas (clases) esperadas para cada una de las 3 muestras (+1 o -1):
| nº | clase |
|---|---|
| x1 | -1 |
| x2 | +1 |
| x3 | +1 |
Dibujad las 2 últimas dimensiones de las muestras -d1 y d3 de la primera tabla- en un eje de coordenadas y veréis como encontráis rápidamente infinitas soluciones que separen las muestras en función de la salida (+1 o -1). Eso mismo hará el sistema, dar una posible solución de todas los hiperplanos (rectas en este caso) que sirven para separar las clases (en entradas posteriores, cuando se traten SVM, se podrá elegir entre el mejor de todos aquellos hiperplanos separadores según un criterio de distancia entre clases e hiperplano).
Con ello (en el main del script) partimos de un vector θ aleatorio (se suele inicializar a 0) y lo ajustamos mediante la función fit para que clasifique correctamente las muestras, minimizando la función objetivo mencionada antes. Una vez finalice, obtenemos detalles sobre la finalización del proceso del solver (valor de f final, nº iteraciones realizadas, vector θ, etc) y la salida de una muestra a clasificar [1,0,5], que corresponde al conjunto de muestras de entrenamiento y conocemos su clase (si hemos dibujado las coordenadas como dije) : -1. La salida del script ejemplo es:
Detalles de convergencia
fun: 0.0
jac: array([ 0., 0., 0.])
message: 'Optimization terminated successfully.'
nfev: 10
nit: 1
njev: 2
status: 0
success: True
x: array([ 1.9997, 4.46 , -0.78 ])
Clase de [1,0,5]: -1
Que coincide con lo que esperábamos, observando que el método ha convergido en 2 iteraciones a la solución θ = [ 1.9997, 4.46 , -0.78 ], además ha clasificado la muestra [1,0,5] que efectivamente pertenece a la clase -1.
Adaline
Adaline es una red neuronal de una capa utilizada en principalmente en regresión lineal. En este caso, el objetivo del aprendizaje es encontrar un vector θ con el que se minimice la diferencia entre θ·x y la salida esperada y para toda muestra de entrenamiento. Del mismo modo que en Perceptron, se minimizará esta función equivalente a resolver el sistema planteado (ahora no se tienen en cuenta solo las mal clasificadas, si no que se quiere minimizar las diferencias entre la RHS y la LHS del todo el conjunto de ecuaciones).En este caso no he encontrado ningún teorema sobre la convergencia excepto éste.
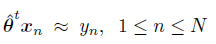{kind=link}
{kind=link}
{kind=link}
El código es el siguiente:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# Adaline.py
from scipy.optimize import minimize
import numpy as np
from Utils import MatLoad
def f(theta,X,Y):
res = ((theta*X)+(-Y))
return (1.0/2.0)*(np.multiply(res,res).sum(axis=1)[0].item((0,0)))
def fit(theta,X,Y):
XROWS,XCOLS,YROWS = X.shape[0],X.shape[1],Y.shape[0]
return minimize(fun=f,x0=theta,args=(X,Y))
def predict(theta,X): return np.inner(theta,X)
def classify(theta,X): return 1 if np.inner(theta,X)>=0 else -1
if __name__ == "__main__":
X = MatLoad("X.np");
Y = MatLoad("Y.np");
XROWS,XCOLS,YROWS = X.shape[0],X.shape[1],Y.shape[0]
theta = np.zeros(XROWS)
res = fit(theta,X,Y)
print "\n Detalles de convergencia \n"
print res
theta = res.x
print "\nClase de [1,0,5]:",classify(theta,np.array([1,0,5]))
Es idéntico al del Perceptron, cambiando la función objetivo de f a f’. Nótese que la minimización de las diferencias entre la LHS y RHS no garantiza resultados correctos en clasificación donde normalmente el conjunto de salidas posibles Y es discreto.
La salida del script es muy similar a la del caso anterior:
Detalles de convergencia
fun: 7.76245804938178e-15
hess_inv: array([[ 4.99999999, -1. , -1. ],
[-1. , 0.26 , 0.18 ],
[-1. , 0.18 , 0.24 ]])
jac: array([ -1.30741529e-10, 3.51008111e-11, 1.42319490e-11])
message: 'Optimization terminated successfully.'
nfev: 40
nit: 5
njev: 8
status: 0
success: True
x: array([ 1.00000026, 0.19999994, -0.40000006])
Clase de [1,0,5]: -1
El conjunto de muestras es el mismo que en el caso anterior, sin embargo, se puede observar que el vector θ difiere del obtenido en Perceptron ya que al modificar la función objetivo se resuelve un problema diferente (éste, se podría haber resuelto utilizando la función leastsq del módulo optimize).
Hasta aquí lo que quería comentar, hay muchísima documentación sobre todo lo que he ido contando y he intentado enlazarlo y simplificarlo en la medida de lo posible para que sea comprensible. En próximas partes comentaré la implementación de máquinas de vectores de soporte SVM, con y sin márgenes blandos (para ver una introducción la clasificación no lineal) y la aplicación de funciones kernel para que los clasificadores implementados sepan discriminar de formas más complejas.
Dejo el código disponible hasta el momento en el repositorio.
Si tienes alguna duda, comentario o sugerencia, notifícanos a través de indeseables.git@gmail.com y si te ha gustado la entrada puedes compartirla!.