
Redes neuronales y autoencoders.
overxfl0w13, 27 Mar 2016Si se ha visto el post anterior, en el que se comentó la idea general del funcionamiento del Perceptron y se propuso una implementación usando Scipy, la definición de red neuronal como un conjunto de procesadores elementales (neuronas) densamente interconectados no nos resultará difícil de entender, ya que no son más que un conjunto de Perceptron dispuestos en cascada.
{kind=link}
Redes neuronales
También llamadas redes neuronales artificiales o procesado distribuido y paralelo, se basan en el mismo principio que Perceptron, funciones discriminantes lineales (FDL) que se determinan mediante el aprendizaje de un vector de parámetros θ resolviendo un problema de optimización en el que se pretende obtener el vector θ que minimice el error cuadrático entre la salida esperada de las muestras de entrenamiento y la salida obtenida por la red neuronal.Este vector de parámetros θ, hace referencia al peso de las conexiones entre las neuronas de la red neuronal (los pesos asociados a cada una de las aristas de la red de la imagen) y es una medida de la complejidad de la red.
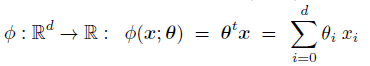{kind=link}
Podemos distinguir 2 aspectos de dichas redes:
-
Topología: hace referencia a la estructura de la red. Definimos una capa como un conjunto de neuronas en un mismo nivel (no hay conexiones entre ellas) y llamaremos a la primera capa (la de las muestras {x1,x2,…,xn}, capa de salida a la última capa y capas ocultas a todas las capas intermedias.
-
Dinámica: describe como fluye la información a través de la red neuronal p.e. para el caso de la topología anterior. Se puede observar como, para cada neurona i de cada capa (oculta y de salida), se calcula su salida en función de los pesos de las aristas que alcanzan a i y del valor de las neuronas j de la capa anterior que alcanzan a i a través de θij aplicando una función g al resultado obtenido (este tipo de redes neuronales se llaman feed-forward, en las solo hay conexiones hacia delante, en concreto, el tipo de perceptron multicapa que comentamos es un caso particular de red feed-forward donde solo hay conexiones a neuronas de la capa siguiente) algunos ejemplos de funciones de este tipo son estos. Hay toda una historia asociada a éstas funciones, pero sólo considerad que éstas funciones se utilizan para que la red neuronal pueda aprender fronteras de decisión más complejas.
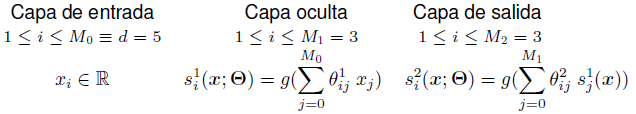{kind=link}
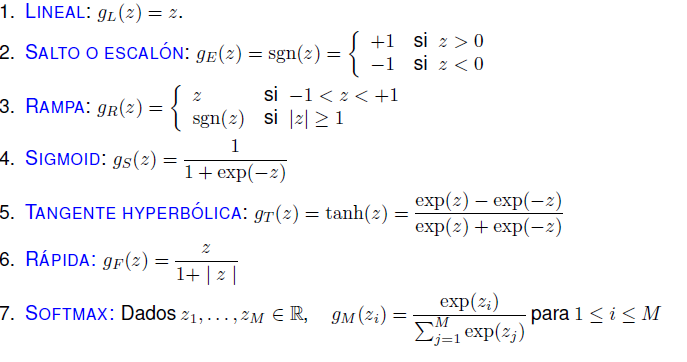{kind=link}
Las redes neuronales pueden aplicarse tanto a regresión (para lo que fueron concebidas) como a clasificación, donde cualquier frontera de decisión basada en trozos de hiperplanos se puede aproximar con un perceptron multicapa de este estilo. Además, pueden ser empleadas tanto en aprendizaje supervisado, como en aprendizaje no supervisado (e.g. autoencoders que veremos en el próximo apartado)
Aparte de lo que he comentado, hay muchísimos teoremas relacionados con las redes neuronales, relativos a la convergencia, al factor de aprendizaje, la intratabilidad del aprendizaje (Blum and Rivest, 1992), el tamaño del conjunto de entrenamiento (Ripley, 1993) y muchos otros que no comentaré, además, a los que estén familiarizados con ésto tal vez les resulte raro que no comente el tan conocido algoritmo de aprendizaje backpropagation, pero me lo ahorraré ya que no deja de ser un método de optimización de descenso por gradiente mediante las funciones de activación g, comentadas antes, que simplifican el cálculo de las derivadas parciales. Si no estáis familiarizados, este proceso vedlo como una caja negra que calcula los pesos óptimos de las conexiones entre las neuronas de la red, para la entrada, lo implementaré con los optimizadores de Scipy (y podemos aplicar métodos no convencionales de optimización para calcular el vector θ, aparte del descenso por gradiente! ). Para implementarlo, basta considerar que el aprendizaje consiste en minimizar el error cuadrático medio de las diferencias entre las salidas esperadas y las obtenidas, e.g. 1 capa oculta, por tanto, podemos considerar dicha función como función objetivo y calcular θ óptimo mediante Scipy, con cualquiera de los algoritmos de optimización implementados.
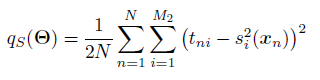{kind=link}
Con ello, ya sé ha visto una pincelada (muy gruesa) de lo básico para comprender mínimamente la implementación de un ejemplo que permite definir una red neuronal y dado un conjunto de muestras supervisadas (o no supervisadas), aprender el vector de parámetros θ para clasificar o hacer regresión.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# NeuralNetwork.py
from scipy.optimize import minimize
import numpy as np
from Utils import MatLoad
from math import e
def lineal(z): return z
def step(z): return 1.0 if z>0 else -1.0
def ramp(z):
if z>=1: return 1.0
elif -1<z<1: return z
elif z<=-1: return -1.0
def sigmoid(z): return 1.0/(1.0+(e**(-z)))
def tanh(z): return ((e**z)-(e**-z))/((e**z)+(e**-z))
def fast(z): return z/(1+abs(z))
def get_weights_submatrices(theta,units_by_layer):
thetas = []
index = units_by_layer[0]*(units_by_layer[1]-1)
thetas.append((theta[0:index]).reshape(units_by_layer[1]-1,units_by_layer[0]))
for i in xrange(2,len(units_by_layer)-1):
thetas.append((theta[index:index+(units_by_layer[i-1]*(units_by_layer[i]-1))]).reshape(units_by_layer[i]-1,units_by_layer[i-1]))
index += (units_by_layer[i-1]*(units_by_layer[i]-1))
thetas.append((theta[index:]).reshape(units_by_layer[len(units_by_layer)-1],units_by_layer[len(units_by_layer)-2]))
return thetas
def generate_theta(units_by_layer):
n_connections = 0
for i in xrange(1,len(units_by_layer)-1): n_connections += ((units_by_layer[i]-1)*units_by_layer[i-1])
n_connections += (units_by_layer[len(units_by_layer)-1]*units_by_layer[len(units_by_layer)-2])
return np.array([1 for i in xrange(n_connections)])
def forward_propagation(theta,X,units_by_layer,factivation):
theta = get_weights_submatrices(theta,units_by_layer)
vec_factivation = np.vectorize(factivation)
res = vec_factivation(theta[0]*X)
for i in xrange(1,len(units_by_layer)-1):
res = np.insert(res,0,[1 for j in xrange(X.shape[1])],axis=0)
res = vec_factivation(theta[i]*res)
return res
def forward_propagation_transform(theta,X,units_by_layer,factivation):
vec_factivation = np.vectorize(factivation)
return vec_factivation(theta*X)
def f(theta,X,Y,units_by_layer,factivation):
res_output_layer = forward_propagation(theta,X,units_by_layer,factivation)
mean_squared_error = (Y-res_output_layer)
mean_squared_error = (1.0/(2.0*X.shape[1]))*np.multiply(mean_squared_error,mean_squared_error).sum(axis=0).sum(axis=1)
return mean_squared_error.item(0,0)
def fit(theta,X,Y,units_by_layer,factivation,max_iter=1000,verbose_convergence=True): return minimize(fun=f,x0=theta,args=(X,Y,units_by_layer,factivation),method="CG",options={"maxiter":max_iter,"disp":verbose_convergence})
def classify(theta,X,units_by_layer,factivation): return forward_propagation(theta,np.matrix(X),units_by_layer,factivation).argmax(axis=0).item((0,0))
def predict(theta,X,units_by_layer,factivation): return forward_propagation(theta,np.matrix(X),units_by_layer,factivation)
if __name__ == "__main__":
## Testing classifier ##
X = MatLoad("X.np"); # Vectores por columnas (N=|cols|, M=|rows|) #
Y = MatLoad("Y.np"); # Vectores por columnas (N=|cols|, M=|rows|) #
XROWS,XCOLS = X.shape[0],X.shape[1]
#### Test NN aleatoria ####
units_by_layer = [XROWS,5,4,2] # Se cuenta la unidad BIAS en la capa oculta (la entrada se asume homogénea) en la de salida NO hay #
theta = generate_theta(units_by_layer)
res = fit(theta,X,Y,units_by_layer,lineal)
print "\n Detalles de convergencia \n"
print res
theta = res.x
print "Clase de la muestra [1,-4,-4]: ",classify(theta,np.matrix([[1],[-4],[-4]]),units_by_layer,lineal)
print "Clase de la muestra [1,4,4]: ",classify(theta,np.matrix([[1],[4],[4]]),units_by_layer,lineal)
print "Regresion con la muestra [1,-4,-4]: ",predict(theta,np.matrix([[1],[-4],[-4]]),units_by_layer,lineal)
print "Regresion con la muestra [1,-4,-4]: ",predict(theta,np.matrix([[1],[4],[4]]),units_by_layer,lineal)
En el ejemplo se puede ver como se carga el fichero que tiene las muestras X y el que tiene las salidas de dichas muestras Y (la salida de cada muestra, ahora es un conjunto de valores que representan el valor esperado en cada una de las neuronas de salida). Después se define una red neuronal especificando el número de neuronas por capa, en este caso, una red con 4 capas (las de entrada y salida y 2 capas ocultas), donde:
-
La capa 0, de entrada tiene tantas neuronas como dimensiones tienen las muestras.
-
La capa 1, (1º capa oculta) tiene 4 neuronas (en el código son 5 porque a las capas ocultas hay que sumarle 1, debido a la neurona de bias (+1) que representa el término independiente en la combinación lineal que define la FLD (en la capa de entrada, la unidad de bias viene representada en las muestras al ponerlas en notación homogénea - poniendo un 1 en la primera posición - y en la capa de salida no hay bias).
-
La capa 2 (2º capa oculta) tiene 3 neuronas (en el código 4 por la razón comentada antes).
-
La capa 3, capa de salida tiene tantas neuronas como dimensiones tiene el conjunto de salida esperado (clases en clasificación o nº dimensiones en regresión).
La salida del script con X, Y (muestras y salidas dispuestas por columnas) es la siguiente:
{kind=link}
{kind=link}
Optimization terminated successfully.
Current function value: 0.075000
Iterations: 41
Function evaluations: 2849
Gradient evaluations: 77
Detalles de convergencia
fun: 0.07500000000044556
jac: array([ -1.40629709e-07, -2.80328095e-07, -2.80328095e-07,
-1.42492354e-07, -2.79396772e-07, -2.79396772e-07,
-1.40629709e-07, -2.80328095e-07, -2.80328095e-07,
-1.41561031e-07, -2.80328095e-07, -2.80328095e-07,
5.92321157e-07, -5.71832061e-07, -5.71832061e-07,
-5.71832061e-07, -5.72763383e-07, 5.92321157e-07,
-5.72763383e-07, -5.72763383e-07, -5.72763383e-07,
-5.71832061e-07, 5.92321157e-07, -5.71832061e-07,
-5.71832061e-07, -5.71832061e-07, -5.72763383e-07,
-4.53554094e-07, -3.41795385e-07, -3.43658030e-07,
-3.41795385e-07, 7.41332769e-07, 5.39235771e-07,
5.38304448e-07, 5.39235771e-07])
message: 'Optimization terminated successfully.'
nfev: 2849
nit: 41
njev: 77
status: 0
success: True
x: array([ 0.29015638, -0.31882134, -0.31882134, 0.29015639, -0.31882129,
-0.31882129, 0.29015638, -0.31882134, -0.31882134, 0.29015634,
-0.31882134, -0.31882134, 0.42504066, -0.07970499, -0.07970504,
-0.07970499, -0.07970508, 0.42504011, -0.07970658, -0.07970659,
-0.07970658, -0.07970657, 0.42504066, -0.07970499, -0.07970504,
-0.07970499, -0.07970508, 1.19071489, -0.49189776, -0.49189632,
-0.49189776, -0.19071479, 0.49189641, 0.49189929, 0.49189641])
Clase de la muestra [1,-4,-4]: 0
Clase de la muestra [1,4,4]: 1
Regresion con la muestra [1,-4,-4]: [[ 1.90000067]
[-0.90000071]]
Regresion con la muestra [1,-4,-4]: [[-0.50000098]
[ 1.50000139]]
Se puede ver que para clasificación (índice de la neurona de la capa de salida que maximice su salida) con esas muestras se comporta bien (dibujadlo en un eje cartesiano teniendo en cuenta la salida de cada muestra e intentad separarlas) y mediante regresión podemos conocer el valor de cada una de las neuronas de la capa de salida. En este ejemplo se ha visto como podemos entrenar de forma supervisada una red neuronal, sin embargo pueden ser entrenadas de forma no supervisada de una manera muy peculiar.
Autoencoders
Un autoencoder es una red neuronal utilizada para aprender codificaciones (p.e. reducción de dimensionalidad, compresión, cifrado, etc) eficientes. Comentaré el autoencoder más básico, que es un caso particular de redes feed-forward muy parecido al perceptron multicapa comentado antes, en el que la capa de entrada y la capa de salida tienen el mismo número de neuronas y en lugar de esperar una salida supervisada Y, se espera la misma muestra de entrada X, consiguiendo con ello que la red aprenda a reconstruir la misma entrada que recibe.
La estructura general de un autoencoder es ésta, y el que emplearé en esta entrada es una variación de éste en el que se ha modificado el número de neuronas en cada capa (ajustándolo a nuestras muestras de entrenamiento y a lo que se quiera conseguir).
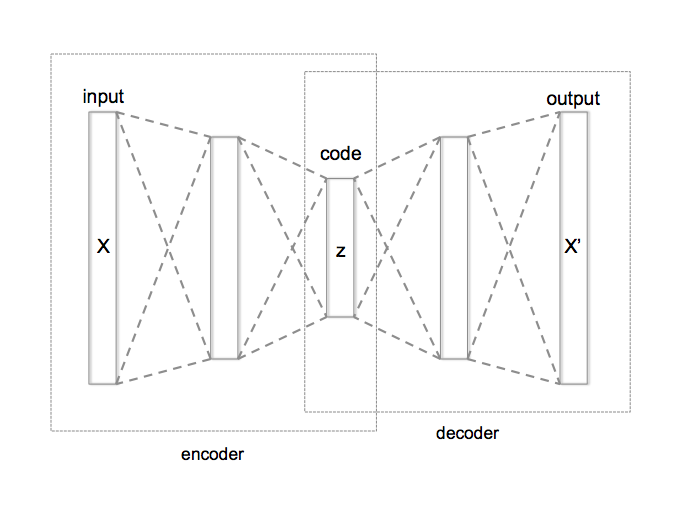{kind=link}
{kind=link}
Si nos fijamos, cuando se entrene la red neuronal de la figura del autoencoder anterior se calcularán los pesos de todas las conexiones de la red y con ello, podemos separar la red en 2 subredes:
-
Subred 1: formada por la capa de entrada y la capa oculta, el resultado obtenido de esta subred es el valor de las neuronas que forman la capa oculta, donde se habrá obtenido una transformación de las muestras reales a un espacio alternativo. Por esta razón, a esta subred se le llama encoder.
-
Subred 2: formada por la capa oculta y la capa de salida, en este caso, partiendo del resultado obtenido en las neuronas de la capa oculta en el paso anterior (resultado del encoder) se obtiene el valor de las neuronas de la capa de salida, que recordemos, sus pesos habían sido entrenados (junto con los demás de la red) para reconstruir la entrada de salida. Con ello, podemos obtener a partir del resultado del encoder el resultado original. Por esta razón, a esta subred se le llama decoder
Por tanto, como se ha visto, al ser el autoencoder simple un caso particular de red neuronal, podemos hacer uso del script implementado en el apartado anterior, que nos permite diseñar redes neuronales y aprender los pesos que minimicen el error cuadrático medio. Consideraré 2 ejemplos de uso de estos autoencoder, el cifrado de bloques de texto y la compresión.
Aplicaciones de Autoencoders: sistema de cifrado por bloques (1)
En el primer ejemplo de aplicación, vamos a ver como haciendo uso de un autoencoder como los explicados arriba, podemos construir un sistema de cifrado por bloques muy simple, en el que el encoder nos permitirá realizar el proceso de cifrado y el decoder el proceso de descifrado. Supongamos que queremos cifrar el mensaje “holablau”, podemos por ejemplo construir 4 muestras de entrenamiento segmentando el mensaje en conjuntos de 2B en secuencia i.e. S={“ho”,”la”,”bl”,”au”} (tendremos que cifrar y descifrar bloques de 2B) , como hay que obtener una representación en un espacio continuo, podemos obtener para cada elemento de S el valor binario de su código ASCII (concatenar los bits de cada uno de los símbolos de cada elemento), con ello, disponemos cada muestra de entrenamiento en columnas (y en notación homogénea con el 1 delante!) y no necesitamos más (recordad que no se requiere información de la salida, solo se pretende reconstruir la muestra original).
Ahora solo queda fijar el número de neuronas en la capa oculta (M1 en el script a 10 , 9 neuronas y la de BIAS) y una vez establecido, ejecutar el script (implementado haciendo uso del script para redes neuronales -MLP- del apartado anterior -NeuralNetwork.py-):
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# AutoEncoder.py
import NeuralNetwork as nn
from Utils import MatLoad
import numpy as np
if __name__ == "__main__":
X = MatLoad("X.np"); # Vectores por columnas (N=|cols|, M=|rows|) #
XROWS,XCOLS,M1 = X.shape[0],X.shape[1],10 # Se cuenta la unidad BIAS en la capa oculta (la entrada se asume en notación homogénea) #
units_by_layer = [XROWS,M1,XROWS-1]
theta = nn.generate_theta(units_by_layer)
Y = X[1:]
res = nn.fit(theta,X,Y,units_by_layer,nn.lineal,max_iter=1000000)
print "\n Detalles de convergencia \n"
print res
theta = res.x
theta = nn.get_weights_submatrices(theta,units_by_layer)
print "Vector original: ",np.matrix([[1], [0], [1], [1], [0], [1], [0], [0], [0], [0], [1], [1], [0], [1], [1], [1],[1]])
encoded = nn.forward_propagation_transform(theta[0],np.matrix([[1], [0], [1], [1], [0], [1], [0], [0], [0], [0], [1], [1], [0], [1], [1], [1],[1]]),units_by_layer,nn.lineal)
encoded = np.insert(encoded,0,1,axis=0)
print "Vector cifrado: ",encoded
decoded = nn.forward_propagation_transform(theta[1],encoded,units_by_layer,nn.lineal)
print "Vector descifrado: ",decoded
En el script se ha entrenado primero el autoencoder con el conjunto de muestras que he mencionado antes y después se ha procedido a cifrar el bloque de 2B “ho” (0110100001101111, y en notación homogénea 10110100001101111), los resultados que se obtienen tras la ejecución del script son:
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 134
Function evaluations: 105841
Gradient evaluations: 336
Detalles de convergencia
fun: 2.399946487631182e-09
jac: array([ -1.10356042e-06, 0.00000000e+00, -1.10356042e-06,
...
message: 'Optimization terminated successfully.'
nfev: 105841
nit: 134
njev: 336
status: 0
success: True
x: array([ -8.47539898e-01, 1.00000000e+00, -8.47539898e-01,
...
Vector cifrado:
[[ 1. ]
[-5.18020183]
[-5.18122276]
[-5.54306646]
[-4.99780952]
[-4.88438915]
[-5.32546369]
[-4.55401426]
[-5.17546803]
[-6.14500501]]
Vector descifrado:
[[ 2.73595684e-05]
[ 9.99997815e-01]
[ 9.99997815e-01]
[ 2.73595684e-05]
[ 1.00001467e+00]
[ 2.51373514e-05]
[ 1.14924639e-05]
[ 2.63763669e-05]
[ 2.73599263e-05]
[ 9.99997815e-01]
[ 9.99997815e-01]
[ 2.63777148e-05]
[ 1.00000102e+00]
[ 1.00000004e+00]
[ 1.00001689e+00]
[ 1.00001368e+00]]
Se puede observar como los 2 bytes “ho”, cifrados mediante el encoder, quedan de la siguiente forma:
[1.0, -5.1802018305848385, -5.181222759796455, -5.543066463152387, -4.997809523535919, -4.884389148007498, -5.325463692424654, -4.554014256199364, -5.1754680337452275, -6.145005007361612]
Podemos transmitir ese cifrado a través de un canal inseguro, habiendo comunicado previamente la clave, que en este caso son los pesos del decoder y el número de neuronas en la capa de salida, mediante un canal seguro p.e. obtenido con criptografía de clave pública.En el destino se descifra mediante el decoder partiendo del cifrado anterior, y se obtiene:
[2.73595684e-05, 0.999997815, 0.999997815, 2.73595684e-05, 1.00001467, 2.51373514e-05, 1.14924639e-05, 2.63763669e-05, 2.73599263e-05, 0.999997815, 0.999997815,2.63777148e-05, 1.00000102, 1.00000004, 1.00001689, 1.00001368]
Si son valores absolutos p.e. 0 y 1, posiblemente no se lleguen a alcanzar nunca debido a que la máxima precisión en coma flotante son 16 dígitos correctos, sin embargo se obtienen valores que prácticamente se corresponden con los valores extremos. En este caso: [0,1,1,0,1,0,0,0,0,1,1,0,1,1,1,1] que se corresponde con el bloque de 2B original: 0110100001101111
De éste modo, podríamos cifrar mensajes completos segmentándolos en bloques de 2B consecutivos e ir cifrando bloque a bloque mediante modos de operación (encadenados o no). Pero si nos fijamos, no solo hemos cifrado, si no que también hemos reducido la información a transmitir (aunque no del todo porque en este ejemplo, al ser la representación discreta y binaria se podría enviar como bloques de bits concatenados y al cifrar de esta manera obtenemos un conjunto de reales que ocupan un mayor número de bytes) pasando de 16 elementos (2B por bloque) a 9 elementos. ¿por qué ha pasado ésto?-
Aplicaciones de Autoencoders: compresión (2)
En el ejemplo anterior se ha visto como se ha reducido el número de elementos a transmitir, ¿por qué?, la respuesta es sencilla, si partimos de una muestra con 16 dimensiones y la usamos para obtener una salida en la primera capa oculta(la última del encoder) de la red neuronal entrenada para la reconstrucción de las muestras, si esta primera capa oculta tiene un menor número de neuronas que dimensiones tienen las muestras, estaremos consiguiendo una reducción del número de elementos. En el ejemplo del cifrado se puede ver como cada muestra tiene 16 dimensiones (1 por cada bit del bloque de 2B) y la primera capa oculta tiene 9 neuronas, por lo que pasaremos de tener un bloque de 16 bits del texto sin cifrar a obtener 9 elementos reales de texto cifrado (se ha obtenido una reducción del número de elementos en el espacio original).
Con esto ha quedado una entrada que recoge una pequeña parte de la teoría de redes neuronales y propone una implementación resolviendo el problema de optimización que caracteriza el aprendizaje en este tipo de redes con métodos diferentes a los convencionales (todos los implementados en el módulo optimize de Scipy de ámbito local e.g. gradiente conjugado, L-BFGS, L-BFGS-B, Nelder-Mead etc).
En la siguiente entrada continuaré las entregas de implementaciones alternativas explicando SVM y funciones kernel.
He dejado todo el código nuevo en el repositorio.
Si tienes alguna duda, comentario o sugerencia, notifícanos a través de indeseables.git@gmail.com y si te ha gustado la entrada puedes compartirla!.